

Aujourd’hui, nous allons parler compression, ou plus exactement fichiers compressés. Pourquoi la compression ? Comment compresser ? Nous allons décortiquer les choses simplement avec la première question qu’on peut se poser, peut-être pour les novices : Qu’est-ce que la compression ?
La compression de données ou codage de source est l’opération informatique consistant à transformer une suite de bits A en une suite de bits B, plus courte mais pouvant restituer les mêmes informations en utilisant un algorithme particulier. C’est une opération de codage, elle raccourcit la taille (de transmission ou de stockage) des données au prix d’un effort de compression et de décompression. La décompression est l’opération inverse de la compression.

Il y a 3 type de compression : la compression sans perte, la compression avec perte et la compression presque sans perte. Ils emploient des algorithmes différents. La compression est dite sans perte lorsqu’il n’y a aucune perte de données sur l’information d’origine. Il y a autant d’information après la compression qu’avant, elle est seulement réécrite d’une manière plus concise (c’est par exemple le cas de la compression gzip pour n’importe quel type de données ou du format PNG pour des images synthétiques destinées au Web2). La compression sans perte est dite aussi compactage. La compression avec pertes ne s’applique qu’aux données « perceptibles », en général sonores ou visuelles, qui peuvent subir une modification, parfois importante, sans que cela ne soit perceptible par un humain. La perte d’information est irréversible, il est impossible de retrouver les données d’origine après une telle compression. La compression avec perte est pour cela parfois appelée compression irréversible ou non conservative. Nous en avons parlé dans une chronique précédente consacrée aux formats des fichiers audio, que vous pouvez réécouter dans nos archives si cela vous intéresse. Enfin, les méthodes de compression sans perte significative sont un sous-ensemble des méthodes de compression avec perte, parfois distinguées de ces dernières. La compression sans perte significative peut être vue comme un intermédiaire entre la compression conservative et la compression non conservative, dans le sens où elle permet de conserver toute la signification des données d’origine, tout en éliminant une partie de leur information.
Les formats de fichier de compression sans perte sont connus grâce à l’extension ajoutée à la fin du nom de fichier (« nomdefichier.zip » par exemple), d’où leur dénomination très abrégée. Les formats les plus courants sont : 7z, ace, arc, arj qui date déjà de quelques dizaines d’année ,bz, bz2 (tar peut être utilisé pour créer les archives de ce type notamment sous Mac OSX), cab utilisé par Microsoft comme les mises à jour de windows, gzip pour les bases données, gz (qui est un fichier à une seule entrée, tar peut être utilisé pour créer les archives de ce type), lzh, rar qui est assez connu, RK, uha, xz, Z (surtout sous Unix), zip, zoo, APE ou FLAC pour les flux audio.
Bien qu’il soit possible de le faire, ce n’est pas dans l’intérêt de l’utilisateur de compresser fichier par fichier. Les logiciels sont capables de regrouper et de compresser plusieurs fichiers ou même des répertoires ou des sous-dossiers, en même temps et dans un seul et même fichier dit d’archive. C’est le fameux fichier compressé. Et lors de sa décompression, on retrouvera les différents fichiers à l’identique tels qu’ils étaient avant la procédure.
Abordons maintenant ce qu’on appelle le taux de compression. Et bien en réalité, l’efficacité de compression va dépendre de la nature des fichiers que vous compressez. Le taux de compression est relié au rapport entre la taille du fichier comprimé et la taille du fichier initial . Le taux de compression est généralement exprimé en pourcentage. Un taux de 50 % signifie que la taille du fichier comprimé est la moitié de . La formule pour calculer ce taux est : .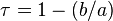 L’algorithme utilisé pour transformer en est destiné à obtenir un résultat de taille inférieure à . Il peut paradoxalement produire parfois un résultat de taille supérieure : dans le cas des compressions sans pertes, il existe toujours des données incompressibles, pour lesquelles le flux compressé est de taille supérieure ou égale au flux d’origine.
L’algorithme utilisé pour transformer en est destiné à obtenir un résultat de taille inférieure à . Il peut paradoxalement produire parfois un résultat de taille supérieure : dans le cas des compressions sans pertes, il existe toujours des données incompressibles, pour lesquelles le flux compressé est de taille supérieure ou égale au flux d’origine.
Question logiciels, vous en avez des payants sous licence comme WinRar ou WinZip pour les plus connus, mais aussi des gratuits comme Quickzip, ou encore Izarc ou 7-zip qui permettent simplifier les opérations basiques, et qui fonctionnent très bien. Il faut juste s’assurer de leur compatibilité selon vos différents systèmes d’exploitation. Et pour les adeptes de l’humour technologique, vous avez NABOB, qui est une parodie d’outil de compression permettant de ramener n’importe quel volume de données à un seul octet ; et bien entendu, il ne permet pas de décompresser, mais en revanche il compresse très bien 😉
Ecoutez le podcast en audio :
